Решение задачи классификации на примере dataset Titanic
Введение
Гибель Титаника является одним из самых печально известных кораблекрушений в истории. 15 апреля 1912 года во время своего первого плавания, Титаник затонул после столкновения с айсбергом, при этом погибло 1502 из 2224 пассажиров и членов экипажа.
Некоторые группы людей имели больше шансов выжить, по сравнению с другими. Например, женщины, дети, пассажиры высшего класса.
В этой статье применяются методы машинного обучения для проедсказания того, какие пассажиры могли выжить в этой трагедии.
Для обучения применяются данные, размещенные на ресурсе Kaggle: Titanic: Machine Learning from Disaster | Kaggle.
Применяются следующие модели машинного обучения из библиотеки scikit-learn.
Nearest Neighbors;
Linear SVM;
RBF SVM;
Gaussian Process;
Decision Tree;
Random Forest;
Neural Net;
AdaBoost;
Naive Bayes;
QDA.
Для каждого из методов считается оценка методом кросс-валидации. Лучший из них применяется для прогнозироавния результата.
Описание dataset Titanic
Набор данных включает в себя два CSV-файла. Файл train.csv
представляет собой обучающий набор, файл test.csv — тестовый набор.
Обучающий набор содержит признак Survived для каждого пассажира,
обозначающий, выжил данный пассажир или нет (0 для умерших, 1 для
выживших).
Каждая строчка наборов данных содержит следующие поля:
Pclass— класс пассажира (1 — высший, 2 — средний, 3 — низший);Name— имя;Sex— пол;Age— возраст;SibSp— количество братьев, сестер, сводных братьев, сводных сестер, супругов на борту титаника;Parch— количество родителей, детей (в том числе приемных) на борту титаника;Ticket— номер билета;Fare— плата за проезд;Cabin— каюта;Embarked— порт посадки (C — Шербур; Q — Квинстаун; S — Саутгемптон).
В поле Age приводится количество полных лет. Для детей меньше 1 года —
дробное. Если возраст не известен точно, то указано примерное значение в
формате xx.5.
Приведение данных
Многие методы машинного анализа работают только с числовыми данными. Поэтому необходимо принять некоторые соглашения по приведению нечисловых параметров к числовым.
Поля Pclass, Age, Sibsp, Parch, Fare являются числовыми и не
требуют преобразования.
Визуальное изучение данных показало, что поля Age и Fare могут
принимать пустые значения. Для пассажиров, значение которых не указано,
предполагается использование медианы среди ненулевых значений этого
параметра.
В поле Sex предполагается значения male заменить на 0, значения
female — на 1.
Поле Embarked также может принимать пустое значение. Для таких записей
поле Embarked будет заполнено значением S.
Преобразование к числу значений поля Embarked происходит следующим
образом: S заменяется на 0, C — на 1, Q — на 2.
Для обучения используются следующие поля: Pclass, Sex, Age,
SibSp, Parch, Fare, Embarked.
Параметры моделей
В целях демонстрации были использованы параметры по-умолчанию.
Nearest Neighbors инициализирется вызовом KNeighborsClassifier(3).
Linear SVM — SVC(kernel-linear , C-0.025).
RBF SVM — SVC(gamma-2, C-1).
Gaussian Process — GaussianProcessClassifier(1.0 * RBF(1.0),
warm_start-True).
Decision Tree — DecisionTreeClassifier(max_depth-5).
Random Forest — RandomForestClassifier(max_depth-5,
n_estimators-10, max_features-1).
Neural Net — MLPClassifier(alpha-1).
AdaBoost — AdaBoostClassifier().
Naive Bayes — GaussianNB().
QDA — QuadraticDiscriminantAnalysis().
Результат
Сравнение оценок классификаторов методом кросс-валидации приведено в таблице и на рисунке.
| Классификатор | Scores |
|---|---|
| Nearest Neighbors | 0.684624 |
| Linear SVM | 0.785634 |
| RBF SVM | 0.632997 |
| Gaussian Process | 0.745230 |
| Decision Tree | 0.806958 |
| Random Forest | 0.811448 |
| Neural Net | 0.756453 |
| AdaBoost | 0.797980 |
| Naive Bayes | 0.782267 |
| QDA | 0.801347 |
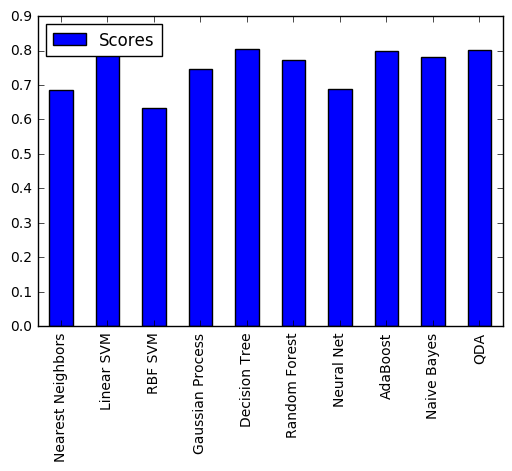
Как видно из приведенных данных, наилучший результат показала модель Random Forest.
Решение, использующее этот классификатор, набрало 0.76555 Kaggle public score.
Результаты исследования опубликованы по ссылке: https://www.kaggle.com/ansmirnov/titanic/titanic-comparison-of-classifiers/.